スクリプトを使用して自動テストを行う
Note
ここでは、Python スクリプトを用いて UDP を使用した自動テストを行う方法を説明します。
サンプルを使ってスクリプトを理解する
AUTOmeal では Python 形式のスクリプトファイルに自動化したい制御・計測・判定の命令を記述し、そのスクリプトを読み込むことでテストを自動化させることができます。
使用するAPI
サンプルスクリプトで使用される UDP 通信の API は以下です。
# エンドポイント名が "Endpoint1" のエンドポイントから、宛先 IP アドレス "192.168.10.11"、宛先ポート 8080 へ、データ [0x01, 0x02, 0x03] を送信します。
am.send_udp("Endpoint1", "192.168.10.11", 8080, [0x01, 0x02, 0x03])
# エンドポイント名が "Endpoint1" のエンドポイントで最後に受信したパケットを取得します。
am.get_latest_udp("Endpoint1", "R")
# 指定したエンドポイントで次のデータを受信するまでタイムアウト付きで待機します。
am.wait_for_next_udp_data("Endpoint1", 5000)
# UDP ストリームを開き、受信したデータを順に取得します。
am.create_udp_stream()
制御では、UDP 通信設定で設定した "エンドポイント名" と、送信先の "IP アドレス"・"ポート番号"、送信したい "データ" を指定してパケットを送信します。送信データには bytes または bytearray を指定できます。
計測では、エンドポイント名と送受信方向 "R/S" を指定すると最新パケットを取得できます。受信を待ち合わせる場合は、タイムアウトまでの時間 (ms) も指定します。
ストリームを使用すると、受信パケットをリアルタイムに順次処理できます。create_udp_stream() は with 構文と組み合わせて使用します。with ブロックを抜けると自動でストリームが閉じられるため、閉じ忘れを防げます。ストリームが開いている間は for ループで受信パケットを 1 件ずつ取得できます。開始・終了のタイミングを細かく制御したい場合は open_udp_stream() / close_udp_stream() を使用してください。詳細はスクリプトリファレンスを参照してください。
ストリームで取得できる UDPRecord オブジェクトには以下のフィールドが含まれます。
| フィールド | 内容 |
|---|---|
time |
タイムスタンプ (timedelta) |
direction |
送受信方向 ("Receive") |
endpoint_name |
エンドポイント名 |
local_ip |
ローカル IP アドレス |
local_port |
ローカルポート番号 |
remote_ip |
リモート IP アドレス |
remote_port |
リモートポート番号 |
data |
受信データ (bytes) |
詳細はスクリプトリファレンスを参照してください。
サンプルスクリプト
エンドポイント名が "Endpoint1" のエンドポイントからパケットを送信し、ターゲットからの応答を受信します。
import automeal as am
# UDP パケットを送信します
# エンドポイント名が "Endpoint1" のエンドポイントから宛先 192.168.10.11:8080 へパケットを送信します。
am.send_udp("Endpoint1", "192.168.10.11", 8080, bytes([0x01, 0x02, 0x03, 0x04]))
# ターゲットからの応答待ちを行います。
am.sleep(0.5)
# 最後に受信したパケットを取得します。
result_udp = am.get_latest_udp("Endpoint1", "R")
if len(result_udp) == 0:
print('受信データはありません。', flush=True)
else:
print(f'Endpoint1 受信データ:{result_udp}', flush=True)
# 次のパケットを受信するまで待機 (無限待ち) し、受信したパケットの表示を行います。
result_udp = am.wait_for_next_udp_data("Endpoint1")
print(f'Endpoint1 受信データ:{result_udp}', flush=True)
# UDP ストリームを開きます (with を抜けると自動でクローズされます)
# ストリームを使用すると、受信パケットをリアルタイムに順次処理できます。
with am.create_udp_stream() as udp_stream:
for data in udp_stream:
record = am.UDPRecord.from_stream_data(data)
print(f'エンドポイント: {record.endpoint_name}', flush=True)
print(f'送信元: {record.remote_ip}:{record.remote_port}', flush=True)
print(f'受信データ: {record.data.hex()}', flush=True)
break # 1 パケット受信したら終了
スクリプトをカスタマイズする
スクリプトをカスタマイズしてみましょう。
テキストデータをエンコードして送受信する
テキストデータを送信する場合はエンコードして bytes に変換します。受信したデータはデコードして文字列に戻します。
import automeal as am
# テキストデータを UTF-8 でエンコードして送信します
am.send_udp("Endpoint1", "192.168.10.11", 8080, "Hello UDP".encode("utf-8"))
# 少し待機します。
am.sleep(0.5)
# 最後に受信したパケットを取得します。
result = am.get_latest_udp("Endpoint1", "R")
if len(result) == 0:
print('受信データはありません。', flush=True)
else:
# テキストとしてデコードして表示
print(f'Endpoint1 受信データ:{result.decode("utf-8")}', flush=True)
# 次のパケットを受信するまで待機します (タイムアウト 5 秒)。
# 5 秒間受信しなかった場合はエラー (例外) となります。
result = am.wait_for_next_udp_data("Endpoint1", 5000)
print(f'Endpoint1 受信データ:{result.decode("utf-8")}', flush=True)
エンドポイントを絞り込んで処理する
ストリームで受信したパケットのうち、対象のエンドポイントのものだけを処理します。
endpoint_name を確認し、continue でスキップすることで対象外のパケットを無視できます。
対象が 1 つの場合は != で比較します。
import automeal as am
TARGET_ENDPOINT = "Endpoint1"
with am.create_udp_stream() as udp_stream:
for data in udp_stream:
record = am.UDPRecord.from_stream_data(data)
# 対象外のエンドポイントはスキップします
if record.endpoint_name != TARGET_ENDPOINT:
continue
# 対象エンドポイントのパケットだけ処理します
print(f'受信: {record.remote_ip}:{record.remote_port} -> {record.data.hex()}', flush=True)
break # 1 パケット受信したら終了
複数のエンドポイントを同時に監視する場合は、セットで管理して not in で絞り込み、endpoint_name で分岐します。
import automeal as am
ENDPOINTS = {"Endpoint1", "Endpoint2"}
with am.create_udp_stream() as udp_stream:
for data in udp_stream:
record = am.UDPRecord.from_stream_data(data)
# 対象外のエンドポイントはスキップします
if record.endpoint_name not in ENDPOINTS:
continue
if record.endpoint_name == "Endpoint1":
print(f'[Endpoint1] {record.data.hex()}', flush=True)
elif record.endpoint_name == "Endpoint2":
print(f'[Endpoint2] {record.data.hex()}', flush=True)
複数パケットをまとめて収集して検証する
指定件数のパケットを収集してから、まとめて内容を検証します。
import automeal as am
MAX_COUNT = 5 # 収集するパケット数
received = []
with am.create_udp_stream() as udp_stream:
for data in udp_stream:
record = am.UDPRecord.from_stream_data(data)
received.append(record)
if len(received) >= MAX_COUNT:
break # 指定件数に達したら終了
# 収集したパケットを検証します
for i, record in enumerate(received):
print(f'[{i}] {record.remote_ip}:{record.remote_port} -> {record.data.hex()}', flush=True)
受信内容に応じて他の制御を実行する
ストリームで受信したパケットの内容を判定し、結果に応じてロジック信号などの制御を行うことができます。
以下の例では、特定のコマンドバイトを受信したときにロジック信号をONにします。
import automeal as am
COMMAND_ON = bytes([0x01]) # ON を意味するコマンド
with am.create_udp_stream() as udp_stream:
for data in udp_stream:
record = am.UDPRecord.from_stream_data(data)
if record.endpoint_name != "Endpoint1":
continue
if record.data == COMMAND_ON:
# コマンドを受信したらロジック信号をONにします
am.write_logic_rpigp10("Board1", 1, True)
break
スクリプトを適切な場所に置く
スクリプトは <プロジェクトルート> の中のフォルダに置くことを推奨しています。
スクリプトを配置するフォルダとしては 2 種類あり、その違いは以下です。
自動テストの実行対象とするかどうかで、どちらに配置するか判断してください。
- <Scripts>
- 自動テストで実行の対象としたいスクリプトファイル。
- <Macros>
- 自動テストで実行の対象としたくないスクリプトファイル。
- モジュールやライブラリ、特定動作をマクロ化したスクリプトなど、他のスクリプトから呼び出して利用することを想定したスクリプトファイルなどはこちらに配置してください。
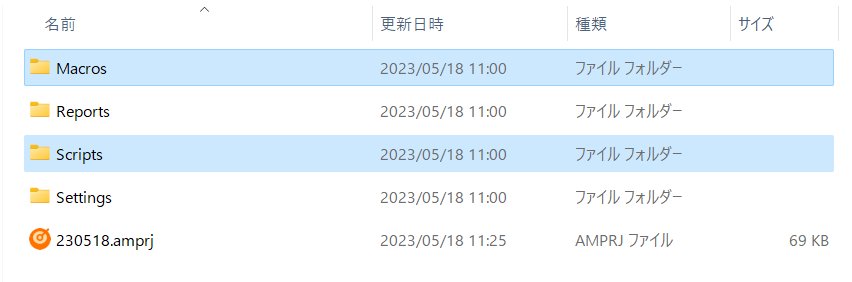
スクリプトを TestRunner アプリ GUI 上から実行する
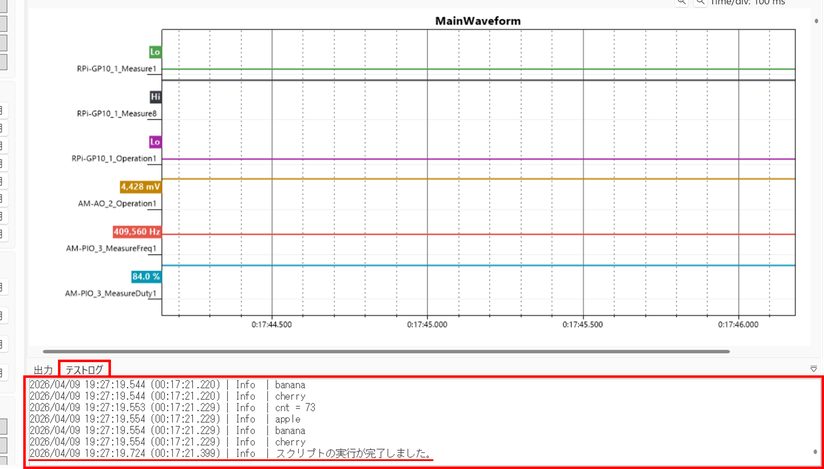
1. テスト実行中の状態で、メニューバーの [テスト] > [スクリプトの実行] をクリックします。
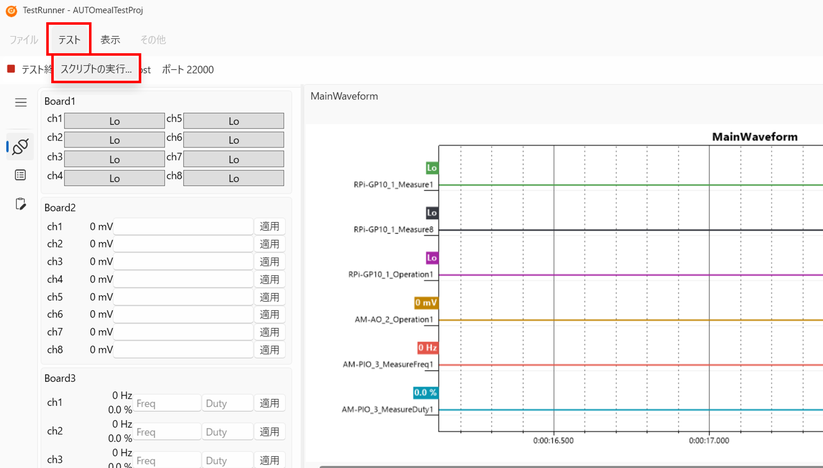
2. Macros または Scripts に配置したスクリプトを選択します。
3. コマンドプロンプトが立ち上がり、スクリプトが実行されるため終了を待ちます。
4. [テストログ] ペインに開始、完了の情報及び、スクリプトに記述したログが出力されます。
スクリプトをコマンドラインから実行する
スクリプトファイルの配置
作成したスクリプトファイルは <プロジェクトルート>\Scripts 以下に配置してください。
フォルダ内にさらにフォルダを作成することもできます。
例
📂Scripts
📄FullTest.py
📂FuncA
📄FuncATest1.py
📄FuncATest2.py
…
📂FuncB
📄FuncBTest1.py
📄FuncBTest2.py
…
テストを実行する
プロジェクトルートでコマンドプロンプトを起動し、コマンドを実行します。
パターンの指定は <プロジェクトルート>\Scripts からの相対パスで指定します。
例 :
-
全てのスクリプトを実行する
TestRunnerCLI -
特定のスクリプトのみ実行する
TestRunnerCLI FuncA\FuncATest1.py -
特定のフォルダ以下すべてを実行する
TestRunnerCLI FuncB\*.py -
特定のファイル名を含むスクリプトを実行する
TestRunnerCLI **\Func*Test*.py
Note
一度の実行で実行されるスクリプトは順不同になります。 実行順を担保したい場合はコマンドを複数回に分けて実行してください。
実行中
実行中はコマンドプロンプトに実行ログと進捗の表示が行われます。
実行完了すると、次のコマンドが実行できるようになります。
結果を確認する
TestRunner アプリ上でのログの確認
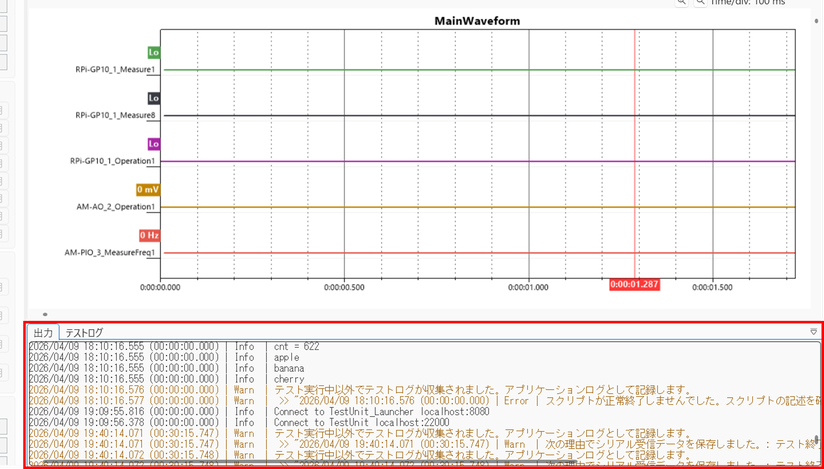
アプリケーション下部の [出力] ペインには、動作ログやエラー詳細情報などが表示されます。 [テストログ] ペインにはテストログやテスト実行中のエラー情報などが表示されます。 テストスクリプトに print 文で記述した内容は [テストログ] ペインに表示されます。
| 種別 | 文字色 | 内容 |
|---|---|---|
| Error | 赤系 | 期待する動作の完了・継続に支障が出た場合の通知です。 |
| Warn | 黄系 | 何らかの不都合が生じたものの、処理の完了・継続に支障がない場合の通知です。 |
| Info | 黒系 | 動作開始・完了などユーザがアプリの状態を把握するための情報です。スクリプトで print を行った場合 Info レベルで出力されます。 |
全体サマリーの確認
Note
全体サマリーは TestRunnerCLI (コマンドライン) から自動テストを実行した場合のみ生成されます。
<プロジェクトルート>\Reports にあるテストランフォルダを確認します。
確認したい実行日時のテストランフォルダを開いてください。
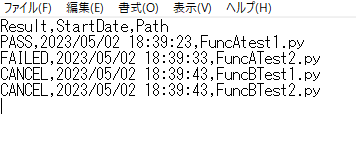
テキストエディタや Excel 等でテストランフォルダ内にある Result.csv を開きます。
Result.csv には実行結果、実行日時、実行したスクリプト名が記載されています。
CSV 形式のため、必要に応じてツール等で結果を集計できます。